If You Only Do Vector Search Your AI App is NGMI

Todays Generative AI apps are reliant on context, but how do we get that context? A lot of noobies will say "Just slap a vector DB on it!" Yeah, cool story. But let's get real, because relying only on vector search? Good luck getting the right context when you actually push to production.
In the ages before ChatGPT, how did we create large scale recommendation systems? How did Amazon, Netflix and TikTok create personlized experiences for their users? It sure wasn't just embedding everything and calling it a day. Todays Generative AI apps are no different. We are just rediscovering old techniques with new tools, namely Search and Recommendation.
Vector Search: Semantic Vibes, Precision Woes
Dismissing the nuance feels easy when you're riding the hype train. But here’s the deal: vector search, while powerful for understanding general semantic meaning (think of vibes), it often falls flat when precision is critical, especially with domain specific jargon. Think law, finance, medicine, engineering... fields where the exact term matters, not just a related concept.
Why? Because vector search maps stuff based on context and usage patterns in broad training data, not the strict definitions or unique identifiers used by experts.
Lets give a quick example:
As humans we know that if we plot 50, 100 and 150 on a number line, we know what they entails. LLMs on the other hand will give you a bunch of stuff that is related to 50, 100 and 150.
An LLM will associate 50 with half or midpoint, while 100 can be seen as full or century. Vector tries to find the semantic meaning behind the words which can break in calculations.
Time is also fuzzy: 'Latest,' 'new,' 'recent' are still vibes, not a strict timeline. How recent is recent? How new is new?
This is why we need hybrid search.
What is Hybrid Search?
To understand hybrid search we need to understand the two types of search:
- Vector Search (also known as semantic search or ANN/KNN - Approximate Nearest Neighbor / K-Nearest Neighbor)
- Full Text Search (FTS)
Vector Search
Or called semantic search, this techniques is the one most abused by the noobies. It catches the semantic meaning behind documents and queries. Great starting point as it helps figure out the vibes or the query and its related concepts. Vector search creates embeddings for the query and documents and then uses cosine similarity to find the most similar documents. The embeddings created are called dense vectors, which are more general and can be used for broad topic exploration. Allowing you to grab semantically similar documents to the query. Vector search also offers more predictable latency compared to sparse search, as the operation is typically consistent for a given vector dimension, regardless of the query terms.
Full Text Search
The most common type of search, this technique is used to find exact matches of the query in the documents. It is great for finding specific terms and is a great starting point. Full text search is often associated with BM25, as quite frankly it is the best. BM25 stands for "Best Match 25", referencing the 25th iteration of the algorithm released back in the mid-90s. As Chang She notes, despite recent claims, BM25 has not been truly beaten for text-based search and remains "the king".
Lets say you want to find the document that contains the term "skibidi toilet". BM25 will find the exact keyword frequency and return the document, unlike vector search that will return a bunch of documents whose vibes match with "skibidi toilet" (so some zoomer documents like "rizz", "kai cenant", "aura farming" etc.). BM25's effectiveness comes partly from its scoring formula, which incorporates Inverse Document Frequency (IDF). As highlighted by the formula Score(D,Q) = Σ IDF(qi) * ..., rarity matters. Terms that are rare across the entire document corpus contribute more to the score for a document containing them. This makes BM25 excellent at finding documents containing specific, less common keywords or jargon.
BM25 is a great starting and ending point for full text search. It creates sparse vectors, which are more specific and can be used for exact keyword/jargon precision.
Combine the Two
Hybrid search is one step beyond just vector search. It can be either full text search + vector search or metadata search + vector search, or metadata + full text search etc. It is a great way to improve the search results. Evaluation results consistently show that hybrid search techniques offer significant improvements over using vector or FTS alone. It is the default for most production grade Generative AI applications that want the right context.
Stop Relying on Vibes, Demand Precision
Vector search is a component, not the whole solution. Especially when dealing with fields where precision and specific terminology are paramount, relying solely on semantic "vibes" is inadequate and potentially dangerous. Combine vector search's contextual understanding with keyword search's exactness using hybrid methods. Build AI apps that are both smart and accurate.
Full Text Search + Vector Search
The Fix: Keyword Precision (BM25) + Semantic Vibes = Hybrid Search
So, what's the answer for apps demanding both relevance and jargon-level precision? Hybrid Search. This intelligently combines the semantic grasp of vector search with the pinpoint accuracy of keyword search (like BM25). As Chang She points out, the fact that vector search (ANN/KNN) and BM25 are complementary and neither strictly dominates the other is precisely the opportunity to combine them for better results.
Keyword search (BM25) excels where vectors fail with jargon:
- Exact Term Matching: It finds documents containing the precise legal statute, financial regulation code, medical term, or drug name. No fuzzy interpretations.
- TF-IDF Smarts: BM25's formula explicitly weights terms based on their rarity (IDF) and frequency within a document (TF, with saturation). This means a rare, specific term (like "mitral valve prolapse" or "Section 230") appearing even once is far more significant than a common word ("heart" or "liability").
- Controlled Ranking: BM25's TF saturation prevents keyword stuffing, while IDF gives weight to critical, unique jargon.
How Hybrid Search Wins (Fusion & Reranking)
Hybrid search typically involves running both semantic and keyword searches simultaneously or sequentially, then merging or re-ordering the results using techniques like Rank Fusion or Model-Based Reranking.
- Rank Fusion (e.g., Reciprocal Rank Fusion - RRF): This method combines results by looking at the ranks from different retrieval techniques, rather than trying to combine potentially incommensurable raw similarity or score values. The RRF formula
RRF(d) = Σ (r ∈ R) 1 / (k + r(d))sums the reciprocal of the document's rank (r(d)) across all retrieval methods (R), withkbeing a constant (often 60) to smooth lower ranks. This approach is computationally very fast and simple, as it doesn't require running another model. It effectively boosts documents that are ranked highly by multiple retrieval methods. - Model-Based Reranking: For potentially higher accuracy, you can use a separate model (a "reranker") to re-score and re-order the top N results retrieved by initial methods (like hybrid search). These reranker models, often from Hugging Face (Cross Encoder, ColBERT, BGE, etc.) or third-party APIs (Cohere, JINA AI), use the actual retrieved text and the original query to determine a new relevance score. While more computationally expensive than Rank Fusion, they are only run on a small subset of the initial retrieval results (e.g., the top 30 from the hybrid search), making them feasible for production.
Benchmark results shared by LanceDB demonstrate the effectiveness of these techniques. For example, on the SQuAD dataset, combining hybrid search with a Cohere reranker achieved a Hit Rate of 92.35%, compared to 81.32% for pure vector search and 87.72% for FTS. These results highlight the substantial performance gains possible with hybrid and reranking approaches.
When to Use What (The Actual Playbook)
- Just Keywords (BM25): High-precision domains where exact terms are non-negotiable. Finding specific legal cases, diagnostic codes, regulatory filings, engineering specs.
- Just Vectors (Semantic): Broad topic exploration, understanding general sentiment, finding loosely related ideas where exact terms don't matter as much. Useful when queries lack specific keywords.
- Hybrid Search (Vector + FTS +/- Rank Fusion): A great starting point for most apps demanding both relevance and some level of precision. Balances semantic understanding with keyword matching. Rank fusion is a fast way to combine initial results.
- Hybrid Search + Reranking: The default for most sophisticated, production-grade apps aiming for the highest retrieval quality. Uses hybrid search for initial recall (getting a broader set of potentially relevant documents) and then a reranker model to refine the ranking based on the actual content.
Below is a simple example of how to implement hybrid search using lancedb (assuming the table is created with a full text search index on the case text column). Format of the table is as follows:
# create full text search index on the case text for legal case search
table.create_fts_index('case_text')
# Create a reranker (Optional but recommended for hybrid search)
# Use a specific model like CohereReranker or a CrossEncoder
# from the LanceDB registry
reranker = ColBERTReRanker() # Example using ColBERT
try:
search_query = "Glew v Harrowell"
print(f"Searching for: '{search_query}'")
print("Embedding the search query using OpenAI...")
client = openai.OpenAI(api_key=openai.api_key)
query_vector = client.embeddings.create(
model="text-embedding-3-small",
input=search_query,
dimensions=512
).data[0].embedding
# Perform the search using hybrid query type
# LanceDB's hybrid query type automatically combines vector and FTS
# if both indices are present.
results = (
table.search(search_query) # Query text passed directly
.query_type('hybrid')
.rerank(reranker=reranker) # Apply the reranker
.limit(5)
.to_pandas()
)
print("\nHybrid search results:")
print(results[['case_id', 'case_title', 'case_text']])
except Exception as e:
print(f"\nAn error occurred during search: {e}")
Jargon Gets Lost in Translation: This is where pure vector search really craps the bed for serious apps. Industries like law, finance and medicine have a lot of jargon and terminology that is not easily understandable by LLMs. It is the same case for basically every single B2B company that I have worked with. LLMs are not able to understand the semantic meaning behind every single industries specific terminology.
Azure AI did a case study on this and found a near 5% improvement in precision (which is similar to my vibe evals, can improve it by looking at the data).
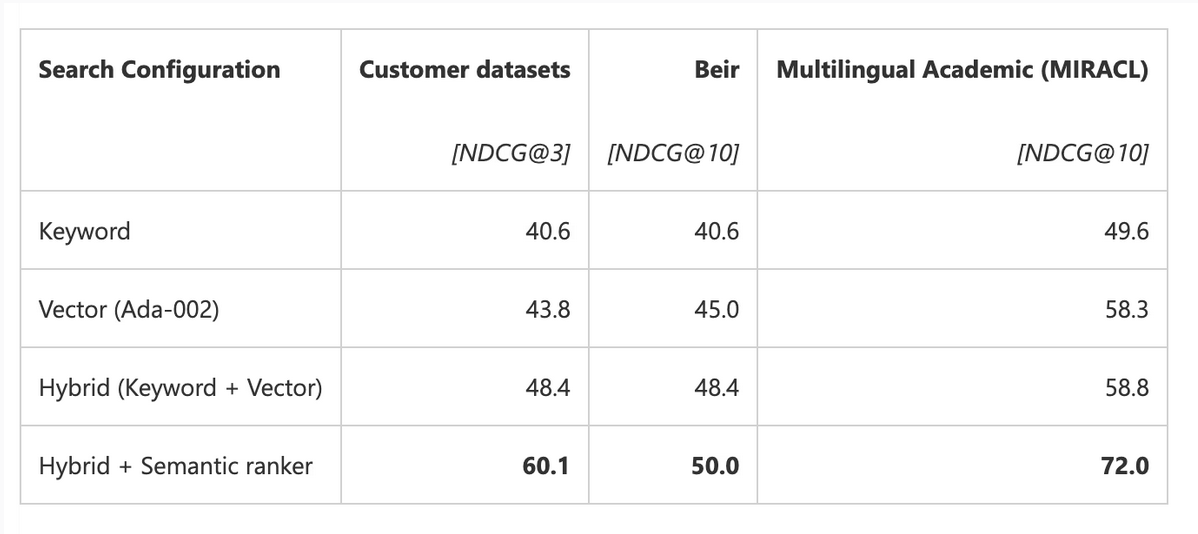
BUT IT FINDS RELATED STUFF! (The Limited Upside)
Metadata Search + Vector Search
Metadata filtering offers another powerful way to add precision and control to vector or hybrid search.
# using mirascope for llm calls
metadata_filter = {"category": "Shipping"}
relevant_question = "What are your shipping options?"
# Use metadata filter in the search
results = vec.search(relevant_question, limit=3, where=metadata_filter) # Assuming 'where' is the parameter for metadata filters
@llm.call(provider="openai", model="gpt-4o-mini")
@prompt.template(
"SYSTEM:
You are a helpful assistant that can answer questions about ecommerce customer support.
CONTEXT:
{context}
USER:
{question}"
)
def generate_response(question: str, context: list[str]): ...
response = generate_response(question=relevant_question, context=results)
Imagine the above scenario where you have a large scale ecommerce site and an user is searching for "Shipping options". You can use metadata search to filter the results to only show shipping options. This is a great way to improve the precision of your search and is a sure fire way to decrease your RAG latency and cost.
Well how do you get the metadata? Two ways: You can have the user provide the type of category question they are asking or have a small but finetuned classifcation model that can classify the question into a category.
Closing Thoughts
There are many ways to improve your Gen AI applications performance and it all starts with retrieval quality. As discussed, building production-ready RAG systems is a process of continual improvement, leveraging composable systems, feedback loops, and evaluations.
Stop limiting yourself to just vector search. As an AI Engineer, it is your duty to experiment with different techniques, evaluate them, and improve your application based on tradeoffs. No technique is inherently better than another, until proven otherwise through evaluations. You need to understand the foundations and the system components, not just rely on popular frameworks.